
Il Problema Invisibile
Ogni giorno, milioni di dipendenti in Europa utilizzano modelli linguistici per le proprie attività lavorative. Scrivono email, analizzano documenti, generano report. In molti casi, queste interazioni contengono dati personali: nomi di clienti, codici fiscali, informazioni sanitarie, dati finanziari.
Il problema è che la maggior parte delle organizzazioni non ha visibilità su cosa viene inviato ai modelli AI esterni. E ciò che non si vede, non si può proteggere.
I Dati nel Contesto GDPR
Il Regolamento Generale sulla Protezione dei Dati (GDPR) è chiaro: l'invio di dati personali a un modello linguistico esterno costituisce un trattamento. Come tale, richiede:
- Una base giuridica legittima (Art. 6)
- Misure di sicurezza adeguate (Art. 32)
- Una valutazione d'impatto (DPIA) quando il trattamento presenta rischi elevati (Art. 35)
- L'applicazione del principio di privacy by design (Art. 25)
La mancata conformità espone l'organizzazione a sanzioni fino a 20 milioni di euro o il 4% del fatturato globale.
I Rischi Concreti
Data Leakage Involontario
Un dipendente che incolla un contratto in un chatbot AI per ottenere un riassunto sta potenzialmente esponendo dati personali di terze parti a un provider esterno. Senza strumenti di intercettazione, questo accade centinaia di volte al giorno in ogni grande organizzazione.
Training Data Contamination
Alcuni provider di modelli linguistici utilizzano le interazioni degli utenti per il fine-tuning dei propri modelli. Dati personali inviati oggi potrebbero riemergere nelle risposte generate per altri utenti domani.
Trasferimento Extra-UE
La maggior parte dei modelli linguistici commerciali opera su infrastrutture cloud statunitensi. L'invio di dati personali a questi modelli costituisce un trasferimento extra-UE, soggetto ai requisiti del Capo V del GDPR e alla giurisprudenza Schrems II.
Impossibilità di Esercizio dei Diritti
Una volta che un dato personale è stato processato da un modello linguistico, diventa tecnicamente impossibile garantire il diritto alla cancellazione (Art. 17) o alla rettifica (Art. 16). Il dato è stato "visto" dal modello e potenzialmente incorporato nei suoi pesi.
Le Contromisure Tecniche
Intercettazione Preventiva
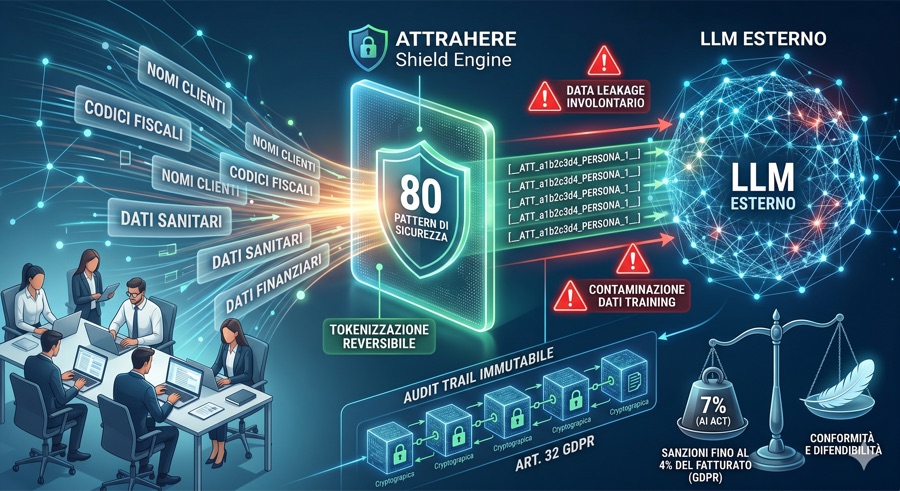
La prima linea di difesa è impedire che i dati personali raggiungano il modello AI. Questo richiede un sistema di pattern matching in tempo reale che analizzi ogni input e identifichi le informazioni sensibili prima dell'invio.
ATTRAHERE Shield Engine implementa esattamente questa funzione: 80 pattern di sicurezza enterprise analizzano ogni richiesta in meno di 12 millisecondi, bloccando o tokenizzando i dati personali prima che lascino il perimetro organizzativo.
Tokenizzazione Reversibile
Quando il blocco totale non è desiderabile, la tokenizzazione offre un compromesso: i dati personali vengono sostituiti con token univoci che preservano il contesto semantico della frase senza esporre le informazioni reali.
Il modello AI riceve ad esempio: "Il cliente [__ATT_a1b2c3d4_PERSONA_1__] ha richiesto..." anziché il nome reale. La risposta viene poi de-tokenizzata prima di essere restituita all'utente.
Audit Trail Immutabile
Ogni intercettazione, blocco o tokenizzazione viene registrata su un ledger crittografico. Questo audit trail costituisce la prova documentale che l'organizzazione ha adottato misure tecniche adeguate ai sensi dell'Art. 32 GDPR.
Il Costo dell'Inazione
Il Garante per la Protezione dei Dati Personali italiano ha già emesso provvedimenti significativi relativi all'uso di modelli linguistici. La tendenza è chiara: le autorità di controllo europee stanno intensificando la vigilanza sull'uso aziendale dell'AI.
Un'organizzazione che oggi non dispone di strumenti per tracciare e proteggere i dati personali nelle interazioni AI si espone a:
- Sanzioni GDPR fino al 4% del fatturato
- Sanzioni AI Act fino al 7% del fatturato
- Danni reputazionali incalcolabili
- Responsabilità ex D.Lgs 231/01 per i vertici aziendali
Conclusione
La protezione dei dati personali nei modelli linguistici non è un problema futuro: è un'urgenza presente. Le organizzazioni che oggi investono in infrastrutture di governance AI non stanno acquistando una tecnologia: stanno costruendo la propria difendibilità giuridica. È in questo contesto che emerge la necessità di una figura dedicata — il Chief Artificial Intelligence Officer — capace di presidiare la governance dei flussi AI a livello organizzativo.
La domanda da porsi non è se i propri dipendenti inviano dati personali ai modelli AI. La risposta è quasi certamente sì. La domanda è: avete gli strumenti per dimostrare di averlo governato?